toitta公式ブログ開設によせて、toittaの自己紹介をします

はじめまして!株式会社はてなの米山(id:yone-yama)です。 生成AIを活用した発話分析ソリューション 「toitta(トイッタ)」を開発しています。
toitta(トイッタ) - AIを活用したインタビュー分析SaaS
この度、2024年7月26日からベータ版として提供してきた「toitta(トイッタ)」を正式版としてリリースしました。 この正式リリースに伴い、今後の情報発信のために「toitta公式ブログ」を開設しました。この記事が記念すべき公開1本目の記事です。
今回は公式ブログの開設によせて、toittaの自己紹介をさせていただこうと思います。少し長いですがお付き合いいただければ幸いです。
toittaとは何か
toittaは、200件超のインタビューを経験して私たち自身が感じた課題をもとに開発した、発話分析のためのソリューションです。
現在toittaを開発している私たちのチームは、新規事業立ち上げをミッションに活動するチームを前身としています。 当時、新規事業の立ち上げや製品改善のために、実際に顧客やユーザーにお話を聞きに行くインタビュー形式の調査を頻繁に行っていたのですが、 この調査の結果分析にあたって採っていた手法が、質的分析手法のひとつである親和図法でした。
新たな発見や深い顧客理解(正確には顧客像、周辺状況、顧客体験への理解)がもたらされるこの手法の威力を強く実感した一方で、日常的に扱うにはコストやスピード感の面で高いハードルがある手法であるとも感じていました。
toittaはこうした親和図法を扱う際の課題を解消し、誰もがこの手法を取り入れて恩恵を享受できるようになることを目指したプロダクトです。 チーム内でリサーチプロセス改善のために開発した内製ツールが前身となっており、自分たちの実体験を色濃く反映させています。
インタビュー型調査の課題を解く親和図法
toittaは、インタビュー形式の質的調査において活用されることを第一義に想定したプロダクトです。
「デプスインタビュー」や「N1インタビュー」と呼ばれるようなインタビュー型の調査は、質問者である自分たちと回答者であるお相手との対話によってなされる調査です。 しかし人間同士の対話を伴う調査という構造上、人間の認知や言語化にまつわる課題が潜んでいます。
例えば、質問者である自分たちは調査を通じて確かめたい仮説や問いを持っているため、一定のバイアスを持って調査に臨んでしまうことがあります。そのため、自分たちの仮説を支持するような情報に目を取られすぎてしまったり、逆に仮説に反するような情報を見逃してしまうことが懸念されます。
さらに回答者であるお相手について言えば、ご自身のことを正しくお答えいただく難しさが課題です。自身の考えや心理を正しく把握・言語化し、それを(多くの場合初対面である)質問者に対して詳らかにするのは、誰にとっても非常に難しいものです。
このような課題を解決するために活用できる手法に、親和図法があります。 発話を小さなデータに分解し、それらデータ間の抽象化を重ねることで主観的な解釈を防ぎつつ対象者の潜在的な心理や価値観を見出す手法です。
私たちのチームではこの親和図法の一つであるKA法を用いてきました。実際の活用を通じて、KA法が人間の言語化能力と認知の限界を克服する助けとなるような、非常に強力な手法であることを実感しました。
親和図法の導入ハードルは高い
しかしながら、自分たちが実際に手法に親しく触れたからこそ、この手法を採択するハードルが高いという実感も同時に持っています。ハードルを高らしめている理由は大きく以下の3点です。
- データを用意する前工程のコスト
- 分析工程でのデータ理解のコスト
- 分析結果を組織全体で理解する難易度
1. データを用意する前工程のコスト
発話をテキスト化し、データとして扱える形式にする前工程は、人の手で行うには途方もないほどの時間を要します。
特に負担が大きいのは「切片化(コーディング)」と呼ばれる作業です。調査対象者の発話を分析に使えるよう小さなデータとして切り分ける作業のことをいいますが、作業にあたっては発話の全文を忠実に書き起こし、対象者の発話だけを選び取り、さらにそこから自分のバイアスを慎重に回避しながら、発話をうまく短文(切片)に切り出す、という工程が求められます。物量が多い上に文章の切り分けや言い換えも必要となる、膨大な人的リソースを費やす作業です。
2. 分析工程でのデータ理解のコスト
前工程で用意した「切片」に対してグルーピング(抽象化)を複数回繰り返し、インサイトを発見することが分析の本工程です。 分析の工程では発話の背景や発言時のニュアンスやトーンを深く理解することが重要ですが、一方で分析対象となる切片は切り出された短い文章なので、周辺の情報は削ぎ落とされてしまっています。
分析の際に「この切片はどういう会話から、どのようなトーンでなされた発話だろう?」という疑問が生じることがままありますが、精査するには分量の大きい発話録を読み込むか、さもなくば録画・録音データから該当地点を探す作業が必要です。分析の精度を高めるために不可欠な作業であるものの作業の負荷は相応に高く、とても根気の要る作業です。
3. 分析結果をチーム全体で理解する難易度
最後に、結果を複数人で扱うことの難しさです。「親和”図”法」という名称であることからも分かるように、この分析手法のアウトプットは図です。例えばKA法における最終的な成果物は「価値マップ」と呼ばれるデータの集合図です。
しかし、大量のテキストデータを省略せずまとめ上げた図であるため、第三者が一見してすぐさま内容を理解するのは非常に困難です。 分析者自身は分析の過程でこれらの内容に深く精通していますが、分析に関わっていないチームメンバーやステークホルダーにはどうしても難解に映ってしまいます。
チームやプロジェクトといった組織単位で活動する場合、分析過程でどれだけ素晴らしい発見があったとしても、しかるべきメンバー間で内容を共有・理解できなければ100%の力を発揮できません。緻密であるがゆえに複数人間で理解することに難儀する点は、親和図法のとても悩ましい側面です。
toittaが提供する価値
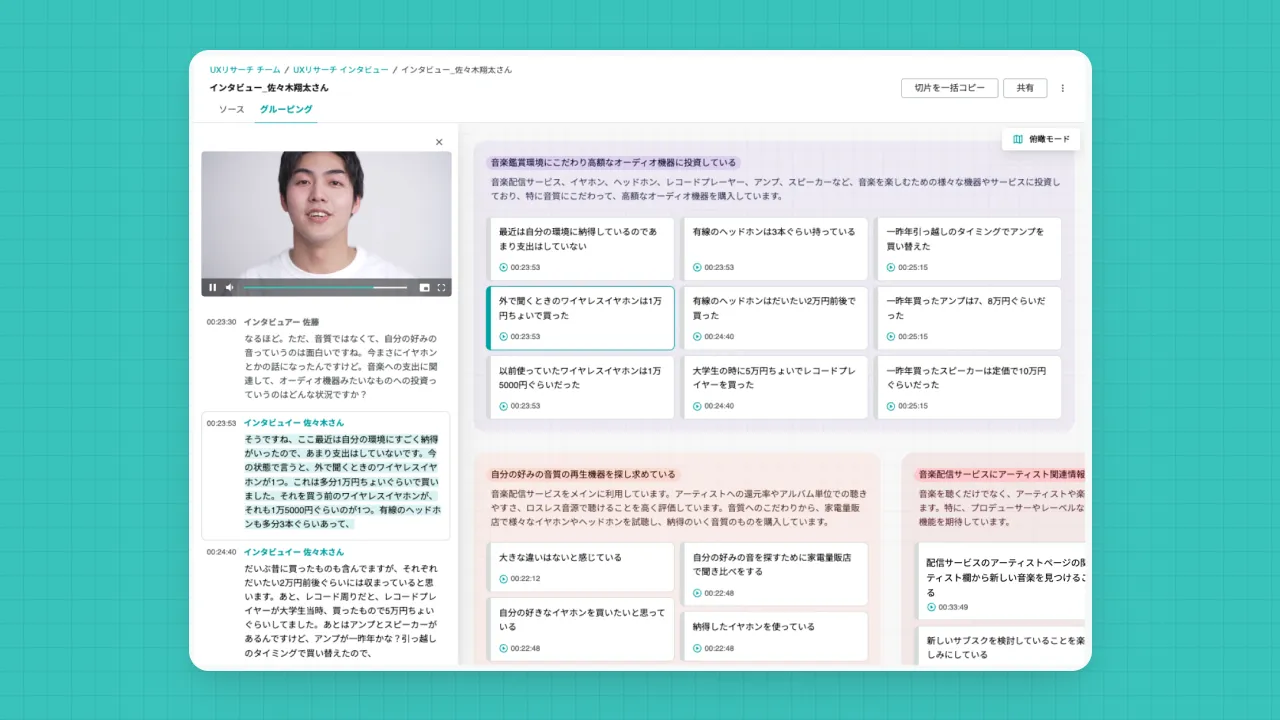
toittaはこのような課題に対し、複数のアプローチで解決を試みています。具体的には、以下の3点です。
- 前工程を省力化し、リードタイムを短縮する
- 分析工程でのデータ理解を深める
- 分析結果をチームで共有しやすくする
1. 前工程を省力化し、リードタイムを短縮する
toittaは高精度な書き起こしと切片データを自動で生成します。所要時間は1時間の動画・音声データならアップロード後およそ30分程度です。 さらに意味的に近しい切片をあらかじめグルーピングした上でインターフェース上で視覚的に表現し、外部ツールへエクスポートすることができます。
データ生成と分析の初期工程を自動化することで、膨大な手作業から解放されることはもちろんのこと、調査ごとのリードタイムを大幅に縮めることにも寄与します。
従来の親和図法での分析を含む調査プロセスでは、データの準備と分析とで数日を要することは珍しくありません。そのため、例えばスクラムでよくある1週間〜2週間のタイムボックスで活動する場合、日々の開発サイクルそのものに分析を伴う調査を組み込むことは困難といえます。日常的に採択できる手法でない以上、ある程度余裕のある四半期・半年に1回などの頻度でまとまった期間を取って行うしかありません。他業務のかたわらで実行する場合にも、調査開始から結果が分かるまで数週間を要することもあるでしょう。
しかしtoittaを使えば、同じ分析がインタビュー終了後すぐに着手でき、分析自体も数時間で終えることができます。高頻度にインタビューを実施しても毎回分析を行うことができるようになりますし、インタビューの結果を翌日や数日後の定例ミーティングで共有することも理論上可能です。 ビジネスの現場で、意思決定に資する情報が「翌日分かること」と「来週分かること」には大きな差があります。分析をいつでも実行でき、その結果をすぐに次のアクションに繋げられるようになる効用は計り知れません。
2. 分析工程でのデータ理解を深める
分析対象となる切片には発話の背景情報やトーンが含まれず、録画や発話録に立ち戻るコストも大きいことは先に述べた通りです。こうした特定の粒度のデータだけでは理解しきれない「発話」という情報の茫漠さを、toittaは「全粒度のデータを一緒に見られる」ことで解決します。
toittaでは録画/録音データ・書き起こし・切片がすべて紐づいたデータ構造を持っており、「逆引きUI」と呼んでいるインターフェースで全データを連動して確認することができます。 トーンやニュアンスは録画/録音データで観察し、前後の文脈や発話の背景は書き起こしを読み返す。このプロセスを、大量の切片を対象に高速に行うことができるため、分析プロセスを加速できることに加え、これまでよりいっそう深い情報理解を助けます。
3. 分析結果をチームで共有しやすくする
分析を通して得た発見をプロジェクトにかかわるメンバー全員の共通認識にすることを助けるため、toittaは各種データの共有機能に当初から注力しています。
例えば外部ツールへ切片データをエクスポートする機能では、データはすべてリンク付きのオブジェクトで出力されます。価値マップを作成しチームで共有する際に、価値マップを構成する個別の切片から元の発話・録画を確認することが可能です。普段お使いのツール(Notion・Slack・Googleスライドなど)で発話を引用することも容易です。
また、切片データには「お気に入り」という機能があり、任意の地点の動画・書き起こし・切片を選択的に閲覧することも可能です。 個別のインタビューの様子をチームメンバーに知ってもらいたいときに使える切り抜き動画のようなものをイメージしていただけるといいかもしれません。1時間のデータをつぶさに見返すのが大変な場合も、重要な部分のみを素早く確認することができるため、速報的な情報共有が可能になります。
今後の展望: さらに顧客の声に向き合うために
繰り返し述べたように、親和図法は調査の品質を高める威力を持ちながらも、相応のコスト、リードタイム、活用の難易度を持つことから採択のハードルが高い手法でした。toittaはまず、親和図法による分析のハードルを適正なレベルまで押し下げることで、インタビュー形式の調査活動がより高い成果をもたらすようになることを目指しています。
しかし、「親和図法での分析を支援する」というステップはあくまで第一歩です。toittaという名前は「ユーザーや顧客が『何と言ったか』に深く向き合える」という製品コンセプトが由来です(なん”といった”か = toitta)。
顧客が何と言ったかに向き合う営みは、リサーチや定性調査という枠組みで語られる以前に、どのビジネスにおいても普遍なものであるといえます。toittaを通じて、この普遍的な営みを広く支援したいと考えています。インタビューを通じて集まった顧客・ユーザーの発話のアウトプット先は、必ずしも親和図法にとどまりません。
例えば、インタビューを実施している最中に文字起こしや切片化がリアルタイムに行えるようになれば、インタビュアーがより瞬時に会話の内容を理解できることでインタビューにおける問いかけの品質を高められるかもしれません。 また、切片単位での分析だけでなく発話本文を構造化(例えば「質問-回答」の形式)できれば、マトリクス形式の表として視覚化するなどしてインタビュー間の共通点・差異の発見に役立てることが可能です。 さらに考えを発展させていけば、蓄積した発話データを元に新たなリサーチクエスチョンやインタビューの設問を考案することも可能かもしれません。
このように、顧客が何と言ったかを示す発話データは無数の可能性を秘めて活用を待っています。toittaはこれらのデータ活用を「顧客の声」に向き合う普遍的な営みであるととらえ、こうした営みの価値を高めることを通じて、顧客の心により深く響くものづくりやビジネスが世に溢れることを目指します。
おわりに
当ブログの1記事目ということでたいへん長文をしたためてしまい恐縮です。最後までお読みいただきありがとうございました。
以後の当ブログは、基本的に機能改善や新機能提供などお知らせ、イベントに関する告知を中心にお知らせしていきます。 イベントについては今後精力的に現時点ですでに開催が決まっているものもあります。ご都合の許す方はぜひ参加いただければ幸いです。


