【機能改善】インタビュー解析AIを ver 2.0 にアップデートしました — 切片がより詳細になり、文脈を掴みやすくなりました
こんにちは!toitta開発チームの米山(id:yone-yama)です。
この度、toitta内のインタビュー解析AIを ver 2.0 にアップデートしました! 今回はtoittaがインタビューの書き起こしから自動生成する「切片」の精度を改善するメジャーアップデートです。切片データがより詳細に、深い文脈を伴って生成されるようになりました。
切片とは
切片という単語に聞き馴染みのない方もいるかもしれないので、まず改めて切片とは何かを説明します。
切片とは、インタビュイーの発話から「ひとつのエピソードや意見」を取り出した短いデータのことです。 toittaでは、質的分析におけるオープンコーディングや、KA法における「出来事」の単位を下敷きに、発話の分析に使えるデータの抽出を行う「切片化」機能を提供しています。
切片というデータの奥深さ
分析に活用するためには、切片は単なる発話の要約/分解ではなく、発言のトーンやニュアンスに忠実で、意味的な一貫性を持つことが求められます。 一方で、分析に用いるデータとしては可能な限り端的で、扱いやすい文量であるべきという側面もあります。両者は明確なトレードオフの関係にあります。
toittaはこれまで数々の試行錯誤を経てこの生成ワークフローを構築・改善してきました。 試行錯誤の末にようやく自分たちにとって期待を大きく超える改善がみられたため、メジャーアップデートという形でみなさまにもお知らせすることにしました。(ちなみに、バージョンを明言すること自体も今回が初です)
ver 2.0 は切片の「おいしい」部分が入ります
今回のインタビュー解析AI ver2.0は、この切片生成処理に大きな改善を入れた新バージョンです。 具体的には、切片に文脈・背景・温度感・手触りが伝わる表現をより忠実に残す改善を行いました。発話分析の中で最も示唆深い、言ってみれば「おいしい」部分をより忠実に残す改善です。 もちろん、従来のデータとしての正確性、扱いやすい粒度、発話の網羅性はすべて維持しています。
既にtoittaをご利用いただいているみなさまには、すでにこの新バージョンが適用されています。(リリース以降新たにアップロードされたファイルが、ver.2.0のエンジンで処理されます) インタビューがどちらのバージョンで処理されたかはバッジからご覧いただけるので、ぜひ過去バージョンで生成された切片と内容を比較してみていただければと思います。
ver 2.0 で改善されたポイント
そうは言ってもどこがどう変わったのか、というのは具体例を見ていただくのが一番早いと思うので、いくつか顕著なケースを新旧のバージョンでご紹介します。 代表的な改善点は、切片が1つにまとまりやすくなったこと、切片に発言のニュアンスが残るようになった点です。
切片が1つにまとまりやすく
ひとつの出来事における行動・思考の順序や要素間の因果関係を、1つの切片を読むだけで理解できるように改善しました。
例1:
もとの書き起こし
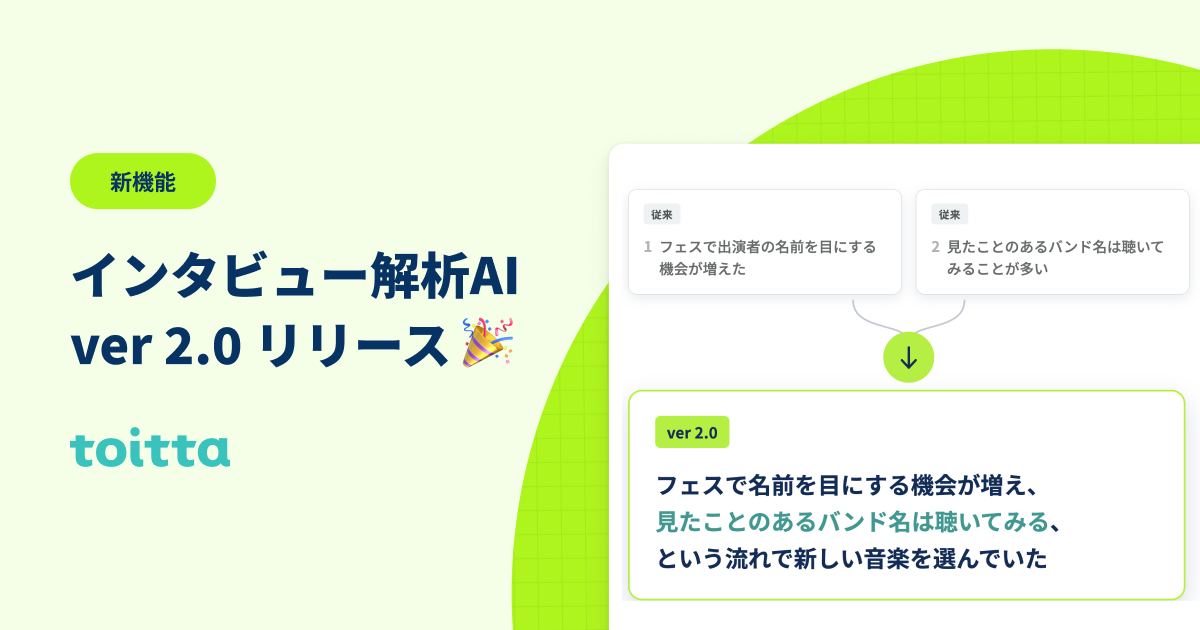
(音楽をどのように見つけ、選んでいるかについての質問) ライブ、特にフェスに行くと、たくさんの出演者の方がいらっしゃって、名前を目にするみたいな機会がぐっと増えたんですね。 このバンド名は見たことあるとか、やっていくとこの名前、見たことあるな。じゃあ、こいつ聞いてみるか?みたいな感じで。
旧バージョン
(1) フェスに行くとたくさんの出演者の名前を目にする機会が増えた (2) バンド名を見たことがあると、気になって聴いてみることが多かった
ver 2.0
フェスに行くとたくさんの出演者の名前を目にする機会が増え、このバンド名は見たことあるから聴いてみる、という流れで新しい音楽を選んでいた
旧バージョンでは独立した2つ切片として表現していた「どのように音楽を見つけ、選んでいるか」についての発言を、「フェスに行き → 目にする機会が増え → 聴いてみる」という行動の流れが見える1文に的確にまとめています。
以下の例でも同様に、旧バージョンでは3つの切片に分かれている発言も、ver2.0では1つの切片で表現しています。
例2:
もとの書き起こし
(音楽に対する支出をどう捉えているかについての質問) 多いとは感じます。 人と比べて、金使ってるんだろうなっていう感覚はありますが、別にこれをやめようとは思わないですね。 自分としては満足がいっています。
旧バージョン
(1)音楽に対する支出は多いと感じている (2)人と比べてお金を使っている感覚はあるが、やめようとは思わない (3)自分としては音楽への支出に満足している
ver 2.0
音楽関連の支出は多いと感じていて、人と比べても金を使っている感覚があるが、やめようとは思わず満足している
例3:
もとの書き起こし
Q: (新しい音楽を探す熱量がずっと継続した秘訣についての質問) A: そうですね、確かに、一番は何でしょう?やっぱり、日々増え続けてくれてるからかなと思います。 サブスクのこの時代、1日6万曲増えるとか言われていて。自分の人生全てを捧げても、聴ききれる量ではないんですけど。
旧バージョン
(1) サブスクの時代は1日6万曲増えると言われている (2) 自分の人生全てを捧げても聴ききれる量ではない (3) 新しい音楽がどんどん増えている
ver 2.0
(1) 音楽への熱量が継続している理由は、日々新しい音楽が増え続けているからだと感じている (2) サブスクの時代は1日6万曲増えると言われていて、自分の人生全てを捧げても聴ききれない量だと感じている
ニュアンスが切片に残る
感情や本人ならではの思考を示すような感情語が、ver 2.0 では切片により忠実に保持されるようになりました。
例1:
もとの書き起こし
(SpotifyとApple Musicの使い分けについての質問) A. あの…大変お恥ずかしいんですが、ほとんどApple Musicしか使っていなくてですね。
旧バージョン
ほとんどApple Musicしか使っていない
ver 2.0
大変お恥ずかしいが、ほとんどApple Musicしか使っていない
ver2.0では、「大変お恥ずかしいんですが」のようなニュアンスを含む文章を維持しています。「Spotify を使っていない自分が恥ずかしい?なぜ?」とひっかかりが残る点が非常に良いですね。
また、以下の例では、特徴的な「死ぬまで遊べるじゃん」というワードを中心に、より本人の感情を示すような表現を忠実に残すようになっています。
例2:
もとの書き起こし
その度に、これ、いいなって思えるものが見つかることの新鮮さみたいなのは、なくならないですね。 死ぬまで遊べるじゃんって思えたんですよね。だから、当然、昔から好きなあの曲とか、あのアルバムみたいなのを聴くこともたくさんあるんですけど。 その一方で、やっぱ、新しく出てくるものや、自分が知らなかった古い有名曲に触れられるのも新鮮で。
旧バージョン
(1) 新しい音楽でいいなと思えるものが見つかる新鮮さはなくならない (2) 死ぬまで遊べると思えた
ver 2.0
(1) 新しい音楽に出会って、これいいなと思えるものが見つかる新鮮さはなくならない (2) 死ぬまで遊べるじゃんと思えるほど音楽の新鮮さが続くと感じている (3) 昔から好きな曲やアルバムを聴くことも多いが、新しく出てくるものや自分が知らなかった古い有名曲に触れられるのも新鮮で楽しいと感じている
他にも改善はいろいろ
今回のバージョンでは、生成処理そのものだけでなく、生成されるテキストに対しての精度評価項目・達成基準も抜本的に見直しました。 このことにより、代表的な改善点以外にも多数の精度改善にも成功しています。
- 5W1Hを適切に判定する
- 話題が飛んだときに発話内の主語・目的語を()で補完する
- 伝聞・推測・持論・事実を切り分けて表現する
- 1切片に含まれる話題・時間・場所の一貫性を保持する
これからも発話データの処理精度改善に投資していきます
コーディングエージェントをはじめとしたAIツールが普及した現代で、貴重な発話データを(toittaのような)特定のプロダクトだけに閉じこめるのはもったいない。より広く多様な活用がなされるべきだと考えています。 この考えのもと、toittaでは外部のAIツール各種からtoittaのデータを活用してもらうため、MCPサーバー(β版)の提供を開始しました。
人間だけでなくAIにも適切に扱ってもらうためには、やはり発話データそのものの精度(正確さ、忠実さ、情報の解像度など)が非常に重要だと考えています。 そのため、これからのtoittaは、こうした発話データの精度改善により一層注力していく予定です。
具体的には、書き起こしの話者判定精度、文字変換精度の向上や、編集操作を支援する機能追加などを提供していく予定です。 今後ともtoittaの進化にご期待いただければ幸いです!


